Deriving the Normal Distribution
This is part of an ongoing series of posts to relearn statistics. I'll attempt to do this by tackling problems that spurred the advancement of statistical methods and techniques. These posts will generally be a bit corny and/or lame, but I do think it helps to have a story like this when tackling a tricky concept. Also I'd like to point out that sections 6,7, and 8 are essentially copied from a UC Santa Cruz lecture I found online. I found it to be an extremely helpful resource in writing this post. It took me quite a bit of time to work through it but it really illustrated the usefulness of the big-O technique. I did fill in some of the steps that the author skipped over so I do feel I made some minor additions that prove useful. The lecture can be found at: UC Santa Cruz lecture
1 Introduction
Rather than retell his story though, I'll be telling a similar one to help illustrate the process. Note that as we begin here, we will be using the binomial distribution as our starting point. I won't be deriving this, but anyone so inclined can check out the "Tools of the Trade" post which gives a little more detail about it.
2 A Gambler’s Lament
-
A coin is flipped 100 times and you must guess it correctly 70 times or more
-
You win 1000 times your wager if you are successful
-
There is a 50% chance to win each coin flip
You know it’s going to be tough, but you do have enough information to calculate the odds of winning. Let’s get cracking.
3 Getting Down with Binomial Distributions
4 More Opportunities Like This
5 A Useful Taylor Series
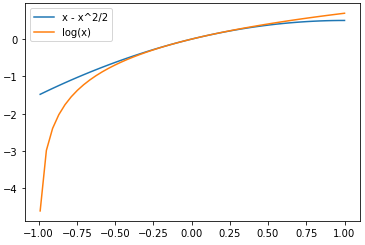
Figure 1: Taylor Series Approximation for log(x)
It looks like the approximation is pretty good in the positive numbers, but how about the negative? Isn't that a huge discrepancy? It might look like it, but we will eventually be exponentiating our numbers to return them to the "real world" in some sense. Here's what it looks like when we exponentiate the results:
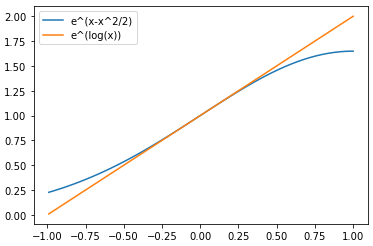
Figure 2: Exponentiation of Taylor Series Approximation of log(x) and actual log(x)
6 Approximating the Exponent Terms
7 Approximating the Square Root Term
8 Your Favorite Distribution's Favorite Distribution
9 But How do we Calculate That?
10 Verifying That Our Approximation Is Good
Historically, people did calculate values of [9] by hand and stored them in reference tables, but we won't be doing that here (it's incredibly tedious). Let's take a brief moment just to check that our approximation accurately models the coin game above and get out of here. First let's check what the entire distribution looks like:
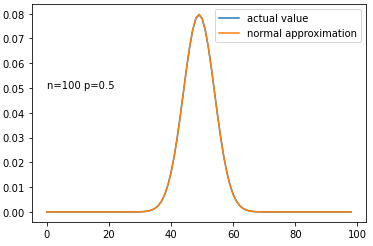
Figure 3: Comparison of Binomial Distribution and Normal Approximation
You can't even see both curves as they're directly on top of one another so I feel pretty good about the approximation. Let's quickly check what the actual and approximate values are for some particular values (and note that due to the nature of discrete vs. continuous values we must add 0.5 to the continuous value):

Figure 4: Table comparing actual and approximated values
11 Wrapping Up
(Not that anyone asked, but the proof found in the "tricks of the trade" section of this statistics blog is excellent for showing the relationship between Stirling and Wallis, but deriving the Stirling formula is where things get a bit tricky. It seems impossible to side step the Euler-McLaurin formula and admittedly this is still a concept I'm learning how to use. It's extremely powerful and looks like something worth investigating more, but it's just taking me some time to wrap my head around it.)
Just want to give another shoutout to the lecture linked above too. I tried doing some of this on my own but it's clear I didn't have the tools necessary to do it.